KVM Forum 2020 是 KVM 社区最为重要和权威的大会。本文为阿里云工程师李伟男和郭成在 KVM Forum 2020 中的演讲内容整理而成。
对于云计算用户来说,过长的 KVM 虚拟机创建及启动时间非常影响体验,特别是超大规格的 KVM 异构虚拟机。以 350G 内存为例,创建时间需要 2 分钟,当用户此时创建虚拟机是用于快速恢复业务时,2 分钟的创建等待时间完全超出用户的可忍受值。另外,对于云计算的后台管控系统而言,过长的阻塞时间极大地影响了系统调度效率。
一直以来,阿里云异构计算团队在 KVM 性能优化方面都有大量的投入,积淀了大量实战经验。
阿里云异构计算团队创新性地提出了一种显著优化带有 透传 (pass-through)设备 的KVM 虚拟机创建及启动时间的方法,虚拟机的启动时间不再随着分配内存的大小而显著增加,即使虚拟机被分配了几百 G 甚至更多的内存,用户感知的启动时间依然没有明显增加。
在这套技术优化方案下,对于 350G 内存的虚拟机,创建及启动时间可从原来的 120 秒以上降低到 20 秒以内,效率整整提升了 6 倍以上;对于 T 级内存的虚拟机,预计创建效率可以提升 10 倍以上。
作为 KVM 社区最为重要和权威的大会,KVM Forum 2020 有 3 个议题是与 KVM 虚拟机创建及启动速度的优化有关,分别来自阿里巴巴、英特尔和滴滴,可见 KVM 社区及云计算业界对此问题的重视程度。阿里云工程师李伟男和郭成在 KVM Forum 2020 上详细介绍了阿里云 KVM 虚拟机创建及启动时间优化的具体技术实现,本文根据其演讲整理而成。
# 发现问题
内存越大、启动越慢, DMA 映射 执行是耗时大户
众所周知,PCI 设备透传是 KVM 虚拟化应用中一个非常重要的场景,而 VFIO 是当前最为流行的 PCI 设备透传解决方案,为了能够在应用层提供高效的 DMA 访问,在启用 VFIO 设备之前,需要将分配给虚拟机的所有内存都锁定并进行 IOMMU 页表的创建。
这么做的原因在于,DMA 访问可能覆盖整个虚拟机的内存空间,并且 DMA 访问的内存不能被 换出 (swap)。所以,如果能够在物理设备 DMA 访问之前得知将要访问的地址空间,就可以在运行中进行内存 _锁定 (pin)_及 IOMMU 页表的创建。但目前并没有一个简单、高效的方法能够完成这一操作。为了虚拟机及设备的高效运行,目前开源社区采取的办法是在虚拟机创建时将所有分配给它的内存进行锁定并创建 IOMMU 页表(DMA 映射 (map))。
由于 DMA 映射是一个相对比较耗时的操作,在虚拟机内存相对较小时,总体耗时是可以接受的。但随着虚拟化市场及技术的发展,越来越多的用户开始使用超大规格的虚拟机,内存资源已从 4G 增长到 384G 甚至更高,随之带来的 DMA 映射时间消耗问题也日益突出。
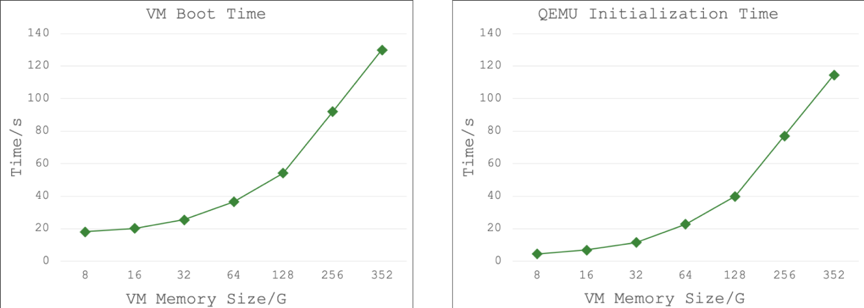
图 1:虚拟机的创建及启动时间与内存大小关系
如图 1 所示,以开源社区的 KVM 虚拟化组件及 Ubuntu 18.04 虚拟机为例,在虚拟机内存达到 350G 以上时,整个 KVM 系统的启动时间将超过 2 分钟,其中绝大部分时间都消耗在 DMA 映射执行操作中。在这 2 分钟里,对于用户来说虚拟机是一个黑盒,用户能做的只有静静等待,甚至不确定虚拟机是否仍然在正常创建中,完全处于未知的状态。
# 设计思路
异步 DMA 映射,完美解决虚拟机创建耗时问题
为了解决这一个问题,阿里云异构计算团队研究了现有的虚拟化技术和实际应用场景。虽然 DMA 映射本身不能省去,但我们发现在系统启动过程中 DMA 访问虽然是随机的、但并不会访问到全部,由此阿里云异构计算团队提出了一种异步 DMA 映射的方法,即在虚拟机创建过程中仅映射有限的内存空间,剩余的大部分内存空间可以在虚拟机启动过程中于后台异步映射完成,从而保证用户可以快速地获取访问虚拟机的权限。
这时,如何保证虚拟机在启动过程中不会有设备通过 DMA 访问到需要异步映射的内存就成为了关键。这个过程中,我们用到了大家比较熟悉的 virtio-balloon,因为 virtio-balloon 设计之初即被用来占用虚拟机内存使用,因此我们提出的解决方案不会涉及到大量、复杂的软件改动,即可完美解决虚拟机创建耗时的问题。
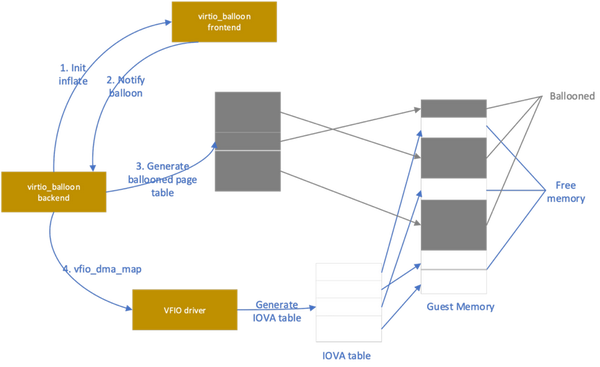
图 2:异步 DMA 映射设计思路
异步 DMA 映射主要设计思路就是:虚拟机创建时,低于 4G 内存空间的 DMA 映射请求会被正常处理,其他内存空间的 DMA 映射操作将会等待 virtio_balloon 前端驱动加载完成后根据实际情况进行处理。
具体的操作流程如下:
首先,确保 virtio_balloon 驱动先于 VFIO 设备驱动加载
这样 virtio_balloon 驱动会在配置空间中获取初始的 balloon 大小,然后再根据 balloon 大小进行实际的虚拟机内存的分配 被分配的内存将从可用内存中去除。在没有释放前,其他设备将无法申请到这部分被占用的内存,那就不会被 DMA 访问到,也就不需要在这之前进行映射。
其次,完成 balloon,获得可异步执行映射内存空间
完成 balloon 的过程是经过很多次 inflate 操作完成的。 每次操作完成后,前端的 virtio_balloon 会通知后端完成的 inflate balloon 大小及其对应的 PFN,位于宿主机上的后端驱动收到通知后,会将 PFN 从消息队列中解析出来,并转换为 IOVA 记录在 ballooned 页表中。 待 balloon 完成后,后端驱动会得到一张完整的被 virtio_balloon 占用的内存页表,这部分的内存空间即是可以异步执行映射的部分。没有在页表中的内存可能会被其他设备通过 DMA 访问,因此需要即刻完成映射操作。
最后,在保证虚拟机系统可继续正常启动的情况下,异步 DMA 映射正式开始
通过向 virtio_balloon 前端驱动触发 deflate 操作,从而向虚拟机归还一定大小的内存. 前端 virtio_balloon 驱动会将释放的内存地址同步给后端驱动,后端驱动接收到被释放的内存地址空间后,触发同步的 DMA 映射,通过分步的 deflate 及映射,慢慢完成全部内存的映射、锁定,从而使虚拟机恢复到完整内存资源可用状态。
# 具体实践
三个关键点优化,进一步优化启动时间
在具体的实践中,我们进行了 “气球” 临近地址空间自动合并、增加单次 “气球” 页面大小和预处理机制等三个关键点的优化,以进一步优化启动时间。具体优化如下:
- balloon 的临近地址空间自动合并。 通过合并多个 balloon 的临近内存地址空间,可以显著地减少触发 DMA 映射的次数。因为 virtio_balloon 会在系统启动初期被加载,此时的内存使用较少,virtio_balloon 申请到的内存地址绝大部分是连续的,临近内存地址的可合并率非常高。
- 增加单次 balloon 页面大小。 内存资源已经不再是非常稀缺的资源,当前 virtio_balloon 前端驱动中基于小页(4KB)大小的内存申请机制已经不太适合当前大规格实例的业务场景。基于业界用户实际应用场景的分析,我们将 virtio_balloon 单次申请的内存大小从 4KB 提高到 2MB,这一举措可减少约 98% 的前后端通信消耗,从而显著减少了不必要的 CPU 资源占用。
- 预处理机制。 为了更快的完成异步 DMA 映射操作,其实可以预先开始进行 DMA 映射操作,而不是等待 deflate 触发并收到 virtio_balloon 前端驱动发出的通知才进行。在接收到前端发出的通知后,只需要做释放地址已映射命中检测即可。如地址未命中则可以插入 DMA 映射操作,若命中则可以更快地返回通知给虚拟机进行后续的 deflate 操作。
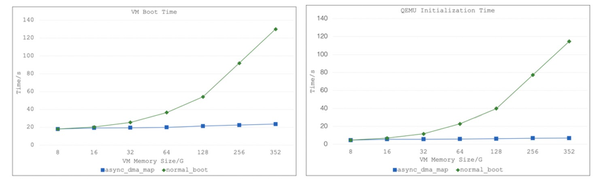
图 3:VM 启动时间与内存关系(左)、QEMU 初始化时间与内存关系(右)
如图 3,经过上述的优化(初始保留 8G 内存给虚拟机),我们看到随着分配给虚拟机的内存增加,KVM 虚拟机的启动时间及 QEMU 初始化时间均没有明显增加。**即我们将 350G 内存 KVM 虚拟机的创建及启动时间从原来的 120 秒以上减少到 20 秒以下,QEMU 初始化时间缩减到 7 秒以内。对于 T 级内存的用户,预计效率可提升 10 倍以上,**可以极快地获得虚拟机的访问控制权限。
# 结语
未来,我们将持续依托阿里云智能,致力于云计算产品的性能及用户体验的优化,为用户提供便捷、高效的弹性计算产品。