摘要.
何为 “三高” 程序员,当然不是指高血压、高血糖、高血脂,而是高学历、高薪资、高颜值。那么 Mysql 的 “三高” 又是什么呢?
# 前言
小伙伴们在项目开发中,无法避免的要跟数据库打交道,一般在互联网公司所采用的数据库都为 Mysql,而且创业公司都采用的单机方式。
这种方式自己玩玩可以,运用到实际项目中,那肯定要挨批的。一方面数据不安全,万一数据库的电脑磁盘坏了,就坑了。另一方面数据库的并发能力是有限的,一般并发数 200~500 就差不多了,当然你要继续往上增,也是可以的,那就影响整体 Mysql 的响应时间。
今天老顾来讲讲 Mysql 的三高集群架构,所谓三高,就是**“高可用”、“高负载”、“高性能” 的架构**方案。
老顾这里说明一下,只是从整体上面介绍集群方案,不会那么深入;但会讲一些网上缺失的、而且很重要的思想。了解全面架构是非常重要的,具体细节自行查阅。
# 主从架构
Mysql 的主从架构是最容易想到的,先来个图:
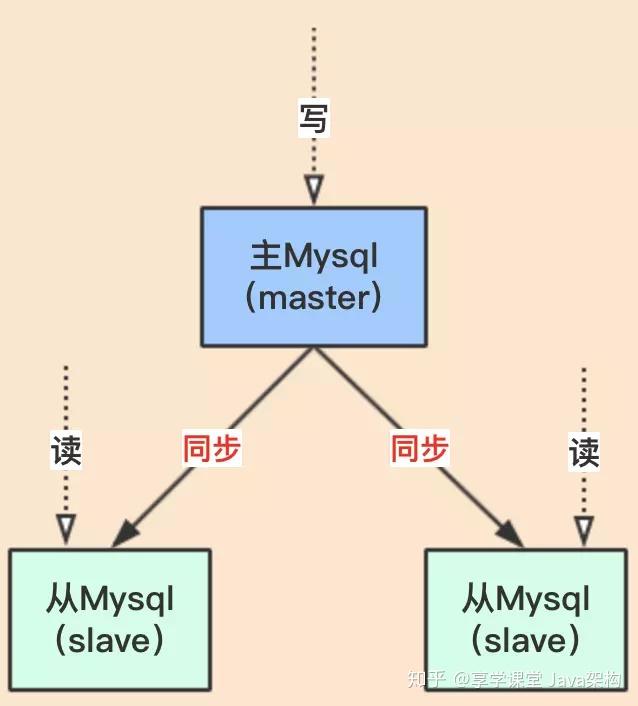
主从方案是我们很多中间件采用的方式,Mysql 的主从方式,数据由主 Mysql 同步到从 Mysql中,数据同步是单向的。
同步的方案有几种方案(异步、同步、半同步),网上介绍很多,老顾就不详细讲了。
主从方案的特点:
1、解决了数据安全问题
2、结合一些中间件(如:mycat)或工具(如:sharding-jdbc)实现读写分离;提高 Mysql 的整体性能 / 负载
注:读写分离含义:数据的更新(即写请求)操作的是主 Mysql,数据再同步到从 Mysql 中;读取数据(读请求)是访问的从 Mysql。
我们从图中可以看出,一主多从的方案中只有一个写节点(主 mysql),一旦主 Mysql 出现问题,整个系统就无法进行写请求,那肯定是不行的。**主 Mysql 有单节点故障隐患,怎么解决?**网上说的方案也有很多,老顾只介绍大厂采用的,比较成熟的方案。
# MHA 方案
MHA 全称 Master High Availability,从名字上面就可以看出它的作用,就是解决主节点的高可用问题。
MHA 目前在 MySQL 高可用方面是一个相对成熟的解决方案,它由日本人开发,是一套优秀的作为 MySQL高可用性环境下故障切换和主从提升的高可用软件。MHA 能做到 0~30 秒之内自动完成数据库的故障切换操作。
MHA 由两部分组成:MHA Manager(管理节点)和 MHA Node(数据节点),如图:
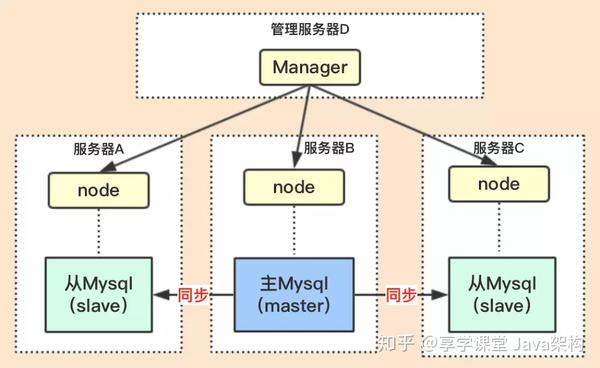
管理节点主要起到监控作用,如果发现主节点不可用,就发起主从切换和故障转移。
目前MHA 主要支持是一主多从的架构,要求至少要 3 个节点,一主二从。
那 MHA 在主节点挂掉后,是怎么进行切换的?
1、主节点挂了,在从节点中重新选举一个新备选主节点,原则是 binlog 最新最近更新的从节点作为新备选主节点。
2、在备选主节点和其他从节点之间同步差异中继日志(relay log)
3、应用从原来的主节点上保存二进制日志
4、提升备选主节点为新主节点
5、迁移集群其他从节点 作为 新主节点的 从节点。
上面介绍了是核心流程,其实 MHA 内部做了很多业务,核心思想就是尽可能的保证数据一致性,不让数据丢失。 虽然 MHA 已经做了很好,但有些场景还是不能避免。还有一个问题就是主节点把数据同步到从节点是有延时的,尤其在高并发情况下,同一刻主节点和从节点数据会不一致。
Mysql 在这方面也进行很多优化,如半同步方式,在 5.7 版本又增加了 after sync 方式,确保数据一致,但多个从节点之间还是存在数据延时。
那有没有一个方案能够确保数据的强一致性?我们接着往下看。
# PXC 方案
PXC 是 percona 公司的 percona xtraDB cluster,简称 PXC。它是基于 Galera 协议的高可用集群方案。可以实现多个节点间的数据同步复制以及读写,并且可保障数据库的服务高可用及数据强一致性。
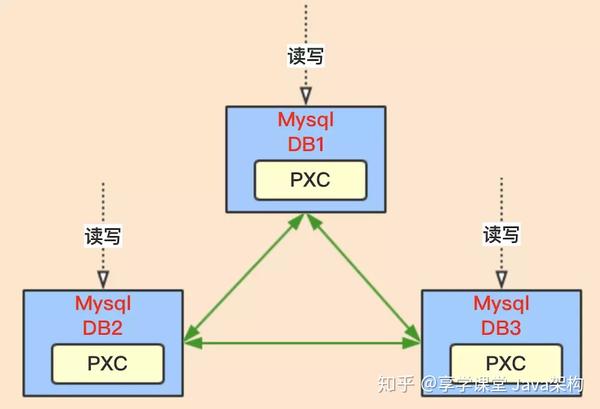
PXC 架构中Mysql 无主从之分,都是相同的。而且每个节点都是能够提供读和写,是不是很酷,那PXC 是怎么实现各个节点数据强一致性的呢?
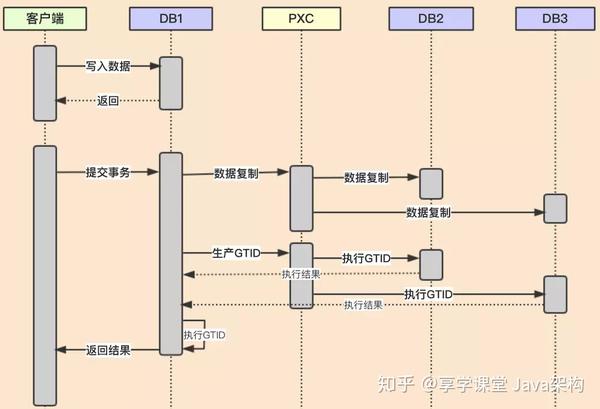
上面是个时序图,就是 PXC 执行的流程,小伙伴们是不是感觉很复杂,老顾可以教大家可以这样理解:
其实就是一句话,PXC 的原理其实在提交事务时,确保所有的节点事务都要成功提交,才返回成功;如果其中有一个不成功,就回滚数据,返回不成功,
正因为这样的原理,就确保数据肯定是一致的,而且是实时一致;当然这样就导致性能有损耗。PXC 另一个好处就是每个节点都可以提供读写请求,不管写在哪个节点,都能够保证数据强一致性。
# MHA 与 PXC
1、MHA 主要写入速度很快,但数据不是强一致性
2、PXC 保证数据强一致性,但写入速度慢
那有没有取他们优点的方案呢?来一个终极方案。老顾告诉小伙伴们,其实很多方案不可能都是优点,没有缺点,不可能很完美,最主要的是要知道在什么场景下运用什么方案。根据 MHA 和 PXC 方案的特点,我们可以结合自己的业务去决定怎么使用它们?
PXC 适合存储高价值的数据,要求数据强一致性,如:账户,订单,交易等等MHA 适合存储低价值的数据,不要求强一致性,如:权限,通知,日志,商品数据,购物车等等
现实情况,很多大厂都是结合使用的,我们看看 2017 年天猫双 11,数据库峰值 4200 万次 / 秒,支付峰值 25.6 万次 / 秒;这个支付峰值已经创造了一个世界记录(国人的骄傲)。
我们发现支付场景的峰值相对其他业务的峰值比较低,这个是因为支付场景肯定是要求数据强一致性的,只要涉及到钱,用户都会很在意。
# 最终推荐方案
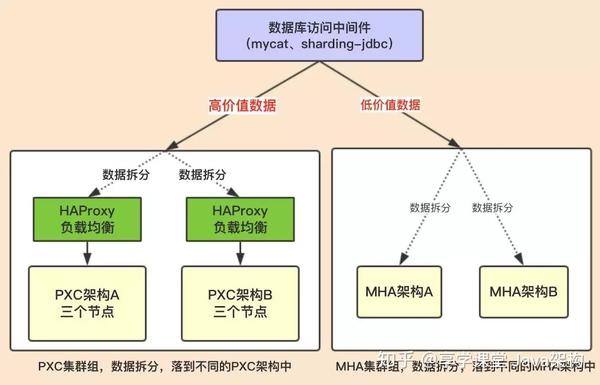
两种方案的结合,因为 PXC 架构都可以写,所以在入口处放一个HAProxy 作负载均衡,客户端只要访问 HAProxy 的地址就行了,不需要知道每个 PXC 节点的地址。
在数据库访问中间件那边肯定要进行业务封装,在设计的时候要明确,哪些数据进入哪个集群环境,当然做的好点,可以配置化(也没有必要,因为业务其实是确定的)
# 总结
很多小伙伴们在网上喜欢问,哪个方案好,哪个方案不好,有没有一个通吃天下的方案,这个是不现实的,很多方案的选择是要结合相关业务场景的。
关于 MHA 和 PXC 很多细节,老顾这里没有介绍,网上介绍的也很多,可以自行查阅。
# 原文链接
https://zhuanlan.zhihu.com/p/76893131 https://zhuanlan.zhihu.com/p/76893131