摘要.

前言:
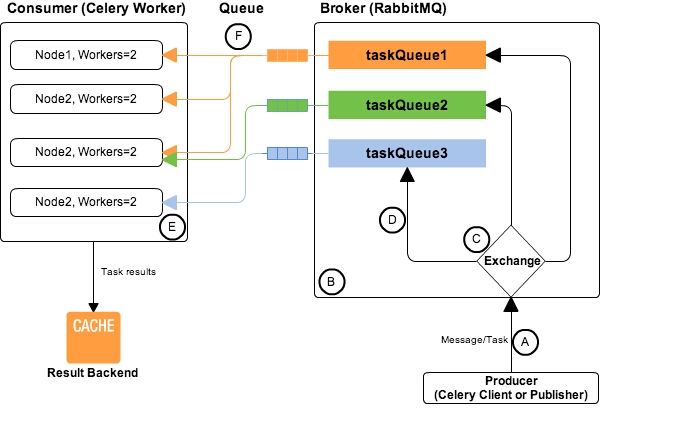
有朋友问我,我那个任务队列是怎么实现,他的疑问其实主要是 celery 不支持多线程。先说说我那实现的方法,其实我的做法和 celery、rq 这样的框架很像的,都是把任务 push 到队列里面,然后 pull 取出任务而已,celery 里面还可以取任务,我这个是通过传送 uuid 来实现的。 朋友问 celery 不支持多线程,那是他没有好好看文档。celery 是支持多任务并发的,哎。。。 好好看文档呀。
原文:http://rfyiamcool.blog.51cto.com/1030776/1530826
队列存储 brokers 用的是 rabbitmq,后面测试下用 mongodb 搞搞。我这里做个测试:
下面是 tasks.py 文件,也就是 celery 能支持异步的函数。
后端启动含有 100 个线程的线程池。
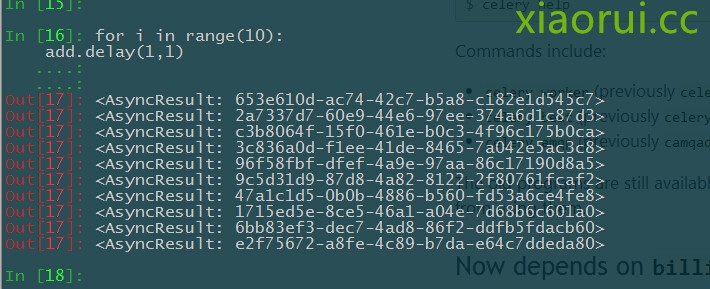
在 ipython 测试的结果:
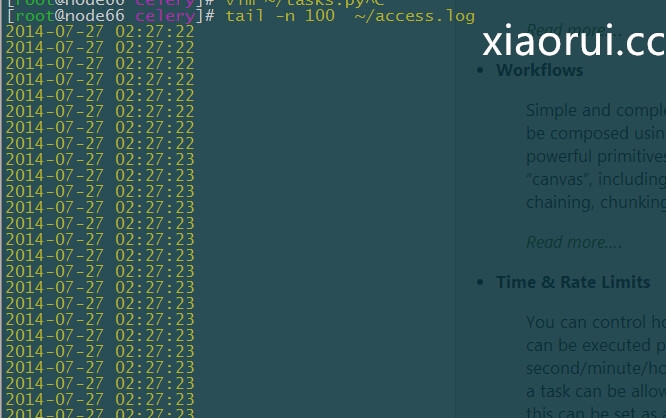
看看我自己输出的日志,结果很明显,是并发的:
原文:http://rfyiamcool.blog.51cto.com/1030776/1530826
celery 是支持好几个并发模式的,有 prefork,threading,协程(gevent,eventlet)
prefork 在 celery 的介绍是,用了 multiprocess 来实现的。多线程就补多少了,估计大家都懂。
说说协程,进程 线程经常玩,也算熟悉,话说协程算是一种轻量级进程,但又不能叫进程,因为操作系统并不知道它的存在。什么意思呢,就是说,协程像是一种在程序级别来模拟系统级别的进程,由于是单进程,并且少了上下文切换,于是相对来说系统消耗很少,而且网上的各种测试也表明,协程确实拥有惊人的速度。并且在实现过程中,协程可以用以前同步思路的写法,而运行起来确是异步的,也确实很有意思。话说有一种说法就是说进化历程是多进程 -> 多线程 -> 异步 -> 协程,当然协程也有弊端,但是如果你的任务类型不是那种 cpu 密集的,那选用协程是个好选择。
但是需要说明的是,虽然 celery 官网提示说,只要在启动 worker 的时候,指明下类型就行了,但是如果你逻辑里面的模块有些不支持协程 gevent 或者是 eventlet 异步的话,他还是会堵塞的。
gevent1.x 之后虽然是支持 subprocess 的用法,gevent 这个模块给非堵塞了,和他有同样功能的 os.popen('sleep 10').read() 是会堵塞的,据说 gevent 官方不支持 popen 的协程的用法。
看了下 celery 针对 gevent 方面的调用,他其实就是引入了 gevent 的 patch 。 那这样会造成堵塞的问题,如果 gevent 不支持这些模块,那。。。。
反之 threading 的用法倒是简单明了,支持把任务放在线程 pool 里面来处理。
话说回来,我的 title 为什么说 gevent 来提高性能。我和小伙伴做一些 gevent 支持的模块写函数,做多任务处理的时候,性能确实要比 threading 要高,还要稳定。
小计:
清理 celery 产生的数据
查看 celery rabbitmq 队列信息
没了 !
© 著作权归作者所有:来自 51CTO 博客作者 rfyiamcool 的原创作品,谢绝转载,否则将追究法律责任 https://blog.51cto.com/rfyiamcool/1530826?spm=a2c6h.12873639.0.0.156b29ecXSTVtb https://blog.51cto.com/rfyiamcool/1530826?spm=a2c6h.12873639.0.0.156b29ecXSTVtb