摘要.
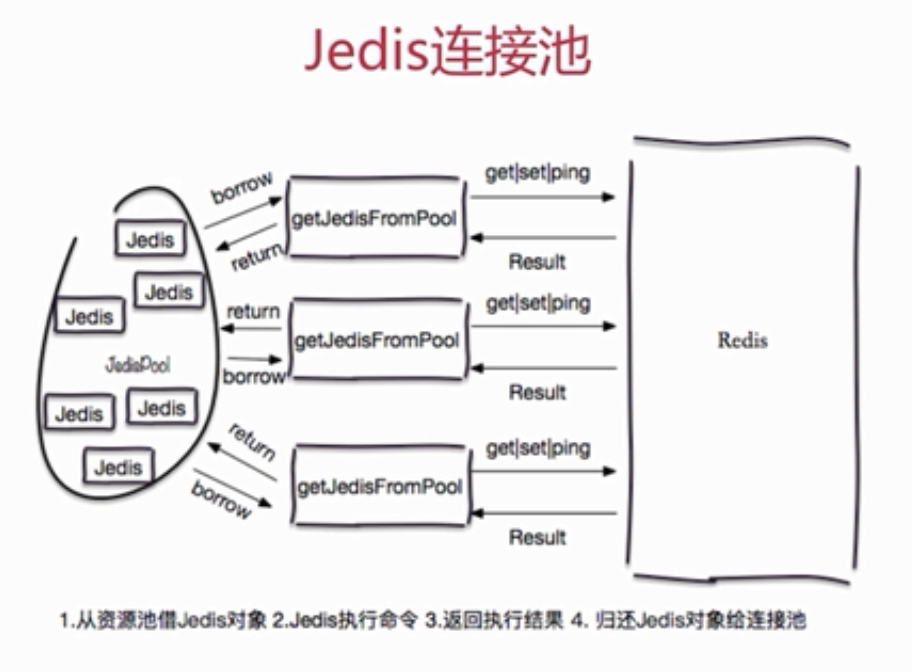
使用普通 jedis 对象和 jedis 连接池之间的差别

keys、sort,exists 等命令
1.keys [pattern]模式查询 O(n) :
keys hello* 以 hello 开头的 key 值。
2.sort 主要对 List,Set,Zset 来进行排序。
sort 命令的时间复杂度是 O(n+mlog(m)),其中 n 是排序列表(集合和有序集合)中元素的个数,m 是返回元素的个数。Redis 在排序前会建立一个长度为 n 的的容器来存储待排序元素,虽然是一个临时的过程,但是多个较大数据的排序操作则会严重影响系统的性能。(这里返回的元素的个数才是真正需要排序的, 但底层到底采用的什么算法来排序的呢?)
在使用这个命令的时候:
1. 尽可能减少排序键中的元素个数,降低 n
2. 使用 Limit 参数只获取需要的数据,降低 n
3. 如果要排序的数据量较大,尽可能使用 store 名来缓存结果。
对于以上问题的解决方案:
在 redis 的设计中体现的非常明显,redis 的纯内存操作,epoll 非阻塞 IO 事件处理,这些快的放在一个线程中搞定,而持久化,AOF 重写、Master-slave 同步数据这些耗时的操作就单开一个进程来处理,不要慢的影响到快的;
同样,既然需要使用 keys 这些耗时的操作,那么我们就将它们剥离出去,比如单开一个 redis slave 结点,专门用于 keys、sort 等耗时的操作,这些查询一般不会是线上的实时业务,查询慢点就慢点,主要是能完成任务,而对于线上的耗时快的任务没有影响
3.exists key_name: 查询 key 是否存在
redis 本身是 key-value 的形式,时间复杂度本来是 O(1), 但是为什么会超时呢?
我们发现在 EXISTS 命令处理函数中实现了清除过期 key 的主动策略,会先调用 expireIfNeeded 函数检查要访问的 key 是否过期,如果过期就 delete 掉这个 key。del 命令在删除元素很多的复合数据类型(list、hash、zset、set)时是一个很耗时的操作。由于存在元素很多的 zset,和 ZADD 一样,在删除 zset 时需要一个一个遍历所有元素,时间复杂度是大 O(n)。由于这个删除操作在 EXISTS 命令的处理函数中执行,所以导致 EXISTS 耗时过长。
上面主要的原因还是我们处理过期 key 的方式的问题,我们处理过期 key:
1. 定期删除:redis 默认是每隔 100ms 就随机抽取一些设置了过期时间的 key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔 100ms 就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载!
2. 惰性删除 :定期删除可能会导致很多过期 key 到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被 redis 给删除掉。然后我们在做每一个操作的时候,都会执行 exists keyname 的操作,如果遇到了过期 key,我们会在这里面执行删除 key 的操作,所以非常花时间。
针对删除大 key 这个问题:
1. 我们可以选择适当增加过期时间,但不能从根本上解决问题
2.redis 作者提供了解决方案,具体就是使用异步线程对大 key 进行删除操作,避免阻塞主线程。
4.smembers 命令:用于获取集合全集,如果一个集合中保存了千万条数据量,一次取回会造成处理线程的长时间阻塞,时间复杂度 O(n)
解决方案:
和 sort,keys 等命令不一样,smembers 可能是线上实时应用场景中使用频率非常高的一个命令,这里分流一招并不适合,我们更多的需要从设计层面来考虑;
在设计时,我们可以控制集合的数量,将集合数一般保持在 500 个以内;
比如原来使用一个键来存储一年的记录,数据量大,我们可以使用 12 个键来分别保存 12 个月的记录,或者 365 个键来保存每一天的记录,将集合的规模控制在可接受的范围;
如果不容易将集合划分为多个子集合,而坚持用一个大集合来存储,那么在取集合的时候可以考虑使用 SRANDMEMBER key [count];随机返回集合中的指定数量,当然,如果要遍历集合中的所有元素,这个命令就不适合了;
5. 生成 RDB 快照文件时,save 命令会带来阻塞:
当然我们采用 bgsave 来 fork() 一个子进程来做数据持久化的 bgsave,虽然在 redis 底层我们采用写时复制策略 copy-on-write(为子进程创建虚拟空间结构,复制父进程的虚拟空间结构,不分配物理内存,就有点像只复制地址,这样可以极大的提高 redis 性能,但如果对父进程有写入操作了,那么我们还是要对子进程复制父进程的物理内存,这是非常耗时的,所以在 bgsave 命令的时候不要对父进程写入)。
在极端的情况下,父进程内存空间特别大,它的页表大小也会有点大,即使不复制物理内存,也可能很耗时哦。
6.mset,mget 也是 O(n)
对于一个 redis 命令生命周期:
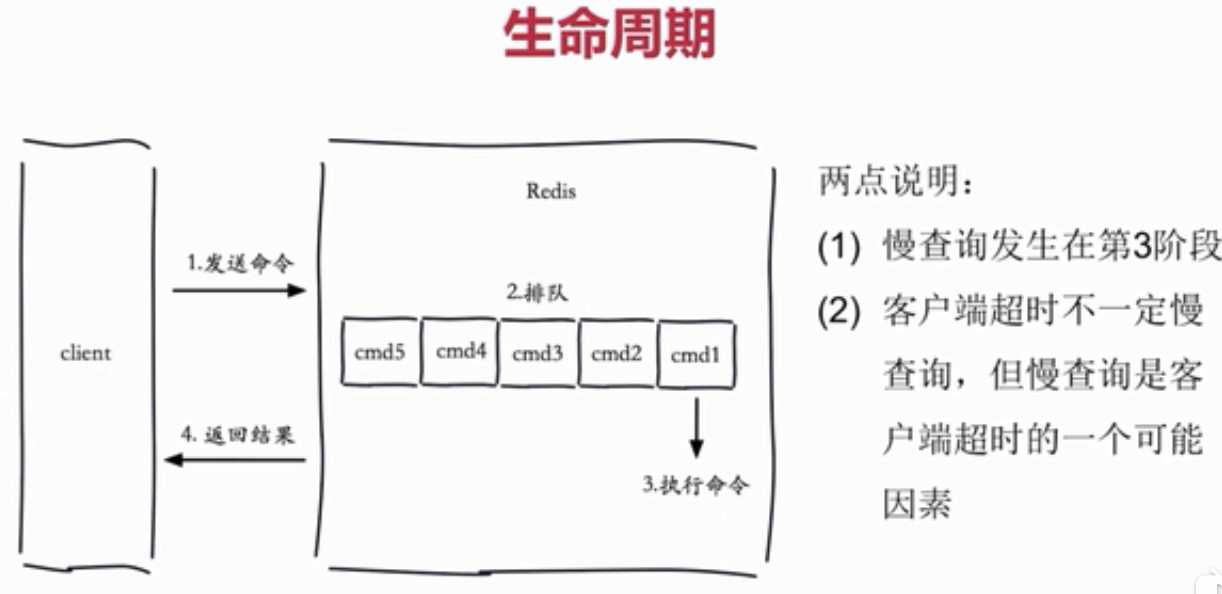
# 慢查询的配置:
1. 慢查询的语句会被放在一个队列里面
slowlog-max-len 这个慢查询队列的长度,这个队列放在内存中不会被持久化(需要定期持久化慢查询)
2. 慢查询阈值
slowlog-log-slower-than(微秒) 当大于这个时间的时候会被放在慢查询队列里面
慢查询命令:
slowlog get [n]: 获取慢查询队列,获取前 n 条慢查询的数据。
slowlog len: 获取慢查询队列长度
slowlog reset: 清空慢查询队列
对于 AOF 阻塞定位:
info persistence
有 aof_delayed_fsync:100 可以看到进行了多少个这样的命令。
pipeline:解决耗时操作的最简单的操作:(简单来说就是减少了客户端发送请求的数量,可以在一定程度上帮助提高性能)
Redis 管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应,简单描述就是一次性可以发送多个请求。
1.pipeline 不是原子操作,其中的所有请求还是按原来的顺序,但中间可能插入其他的请求。
2.pipeline 每次只能作用在一个 Redis 节点上
没有 pipline
Jedis jedis = new Jedis("127.0.0.1",6379); for(int i=0;i<1000;i++) {
jedis.hset("hashkey:"+i,"field"+i,"value"+i);
}
使用 pipline
Jedis jedis = new Jedis("127.0.0.1",6379); for(int i=0;i<100;i++) {
Pipeline pipeline = jedis.pipelined(); for(int j=i*100;j<(i+1)*100;j++) {
pipeline.hset("hashkey:"+i,"field"+i,"value"+i);
}
pipeline.syncAndReturnAll();
}
# 我们也可以通过 pipline 高效插入:方在 2.6 版本推出了一个新的功能 -pipe mode,即将支持 Redis 协议的文本文件直接通过 pipe 导入到服务端。
1. 新建文本文件,创建 redis 命令
SET Key0 Value0
SET Key1 Value1
...
SET KeyN ValueN
- 将这些命令转化成 Redis Protocol。
因为 Redis 管道功能支持的是 Redis Protocol,而不是直接的 Redis 命令。
3. 利用管道插入:
cat data.txt | redis-cli --pipe
https://my.oschina.net/u/4366825/blog/3575225 https://my.oschina.net/u/4366825/blog/3575225